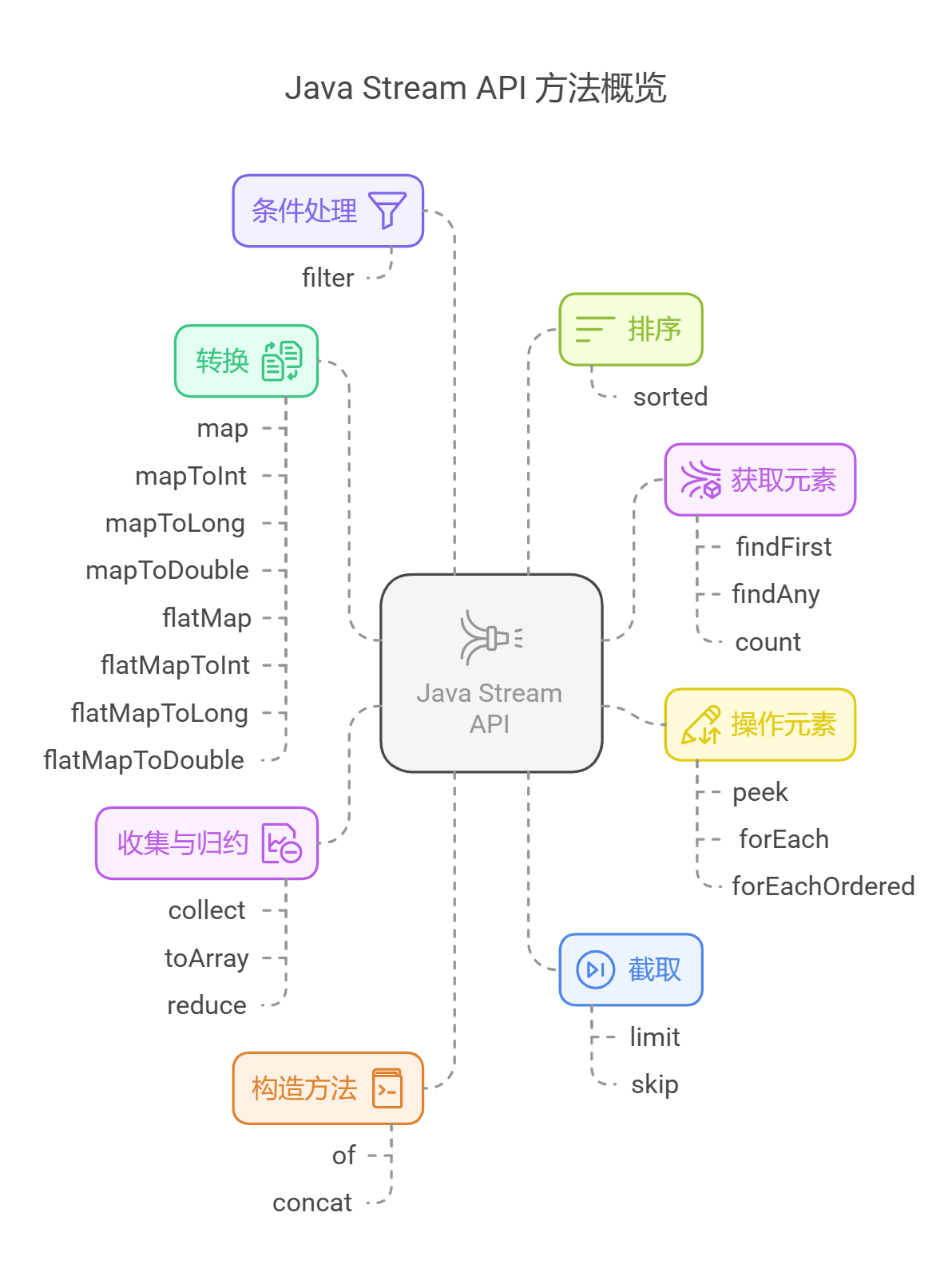
主题
Stream Api
Collection接口提供了 stream()方法,让我们可以在一个集合方便的使用 Stream API 来进行各种操作。值得注意的是,我们执行的任何操作都不会对源集合造成影响,你可以同时在一个集合上提取出多个 stream 进行操作。
我们看 Stream 接口的定义,继承自 BaseStream,几乎所有的接口声明都是接收方法引用类型的参数,比如 filter方法,接收了一个 Predicate类型的参数,它就是一个函数式接口,常用来作为条件比较、筛选、过滤用,JPA中也使用了这个函数式接口用来做查询条件拼接。
public interface Stream<T> extends BaseStream<T, Stream<T>> { Stream<T> filter(Predicate<? super T> predicate); // 其他接口}| 方法名 | 作用描述 |
|---|---|
| 构造方法 | |
| of | 可接收一个泛型对象或可变成泛型集合,构造一个 Stream 对象。 |
| concat | 连接两个 Stream,不改变其中任何一个 Stream 对象,返回一个新的 Stream 对象。 |
| 获取元素 | |
| findFirst | 获取 Stream 中的第一个元素。 |
| findAny | 获取 Stream 中的某个元素,如果是串行情况下,一般都会返回第一个元素,并行情况下就不一定了。 |
| count | 返回元素个数。 |
| 操作元素 | |
| peek | 建立一个通道,在这个通道中对 Stream 的每个元素执行对应的操作,对应 Consumer<T> 的函数式接口。 |
| forEach | 接收一个消费者函数式接口,对每个元素进行对应的操作,执行之后流就被消费掉了。 |
| forEachOrdered | 功能与 forEach 是一样的,不同的是有顺序保证,即对 Stream 中元素按插入时的顺序进行消费。 |
| 截取 | |
| limit | 获取前 n 条数据,类似 MySQL 的 limit。 |
| skip | 跳过前 n 条数据。 |
| 条件处理 | |
| filter | 用于条件筛选过滤,筛选出符合条件的数据。 |
| 排序 | |
| sorted | 有两个重载,一个无参数(按自然顺序排序),另一个有一个 Comparator 类型的参数(自定义排序规则)。 |
| 转换 | |
| map | 接收一个 Function 函数式接口,将原始数据元素映射出新的类型。 |
| mapToInt | 将元素转换成 int 类型,在 map 方法的基础上进行封装。 |
| mapToLong | 将元素转换成 Long 类型,在 map 方法的基础上进行封装。 |
| mapToDouble | 将元素转换成 Double 类型,在 map 方法的基础上进行封装。 |
| flatMap | 这是用来处理特定场景的方法,当你的 Stream 是以下这几种结构的时候需要用到: |
| flatMapToInt | 用法参考 flatMap,将元素扁平为 int 类型,在 flatMap 方法的基础上进行封装。 |
| flatMapToLong | 用法参考 flatMap,将元素扁平为 Long 类型,在 flatMap 方法的基础上进行封装。 |
| flatMapToDouble | 用法参考 flatMap,将元素扁平为 Double 类型,在 flatMap 方法的基础上进行封装。 |
| 收集与归约 | |
| collect | 在进行了一系列操作之后,将结果转换为常用数据结构(如 List、Map 等)。 |
| toArray | 返回数组,有两个重载,一个空参数返回 Object[],另一个接收一个 IntFunction<R> 类型参数。 |
| reduce | 作用是每次计算的时候都用到上一次的计算结果,例如求和操作。 |
of
可接收一个泛型对象或可变成泛型集合,构造一个 Stream 对象。
private static void createStream(){ Stream<String> stringStream = Stream.of("a","b","c");}empty
创建一个空的 Stream 对象。
concat
连接两个 Stream ,不改变其中任何一个 Steam 对象,返回一个新的 Stream 对象。
java
private static void concatStream() {
Stream<String> a = Stream.of("a", "b", "c");
Stream<String> b = Stream.of("d", "e");
Stream<String> c = Stream.concat(a, b);
}max
一般用于求数字集合中的最大值,或者按实体中数字类型的属性比较,拥有最大值的那个实体。它接收一个 Comparator<T>,上面也举到这个例子了,它是一个函数式接口类型,专门用作定义两个对象之间的比较,例如下面这个方法使用了 Integer::compareTo这个方法引用。
java
private static void max () {
Stream<Integer> integerStream = Stream.of(2, 2, 100, 5);
Integer max = integerStream.max(Integer::compareTo).get();
System.out.println(max);
}当然,我们也可以自己定制一个 Comparator,顺便复习一下 Lambda 表达式形式的方法引用。
java
private static void max() {
Stream<Integer> integerStream = Stream.of(2, 2, 100, 5);
Comparator<Integer> comparator = (x, y) -> (x.intValue() < y.intValue()) ? -1 : ((x.equals(y)) ? 0 : 1);
Integer max = integerStream.max(comparator).get();
System.out.println(max);
}min
与 max 用法一样,只不过是求最小值。
findFirst
获取 Stream 中的第一个元素。
findAny
获取 Stream 中的某个元素,如果是串行情况下,一般都会返回第一个元素,并行情况下就不一定了。
count
返回元素个数。
java
Stream<String> a = Stream.of("a", "b", "c");long x = a.count();peek
建立一个通道,在这个通道中对 Stream 的每个元素执行对应的操作,对应 Consumer<T>的函数式接口,这是一个消费者函数式接口,顾名思义,它是用来消费 Stream 元素的,比如下面这个方法,把每个元素转换成对应的大写字母并输出。
java
private static void peek() {
Stream<String> a = Stream.of("a", "b", "c");
List<String> list = a.peek(e -> System.out.println(e.toUpperCase())).collect(Collectors.toList());
}forEach
和 peek 方法类似,都接收一个消费者函数式接口,可以对每个元素进行对应的操作,但是和 peek 不同的是,forEach 执行之后,这个 Stream 就真的被消费掉了,之后这个 Stream 流就没有了,不可以再对它进行后续操作了,而 peek操作完之后,还是一个可操作的 Stream 对象。
正好借着这个说一下,我们在使用 Stream API 的时候,都是一串链式操作,这是因为很多方法,比如接下来要说到的 filter方法等,返回值还是这个 Stream 类型的,也就是被当前方法处理过的 Stream 对象,所以 Stream API 仍然可以使用。
java
private static void forEach() {
Stream<String> a = Stream.of("a", "b", "c");
a.forEach(e -> System.out.println(e.toUpperCase()));
}forEachOrdered
功能与 forEach是一样的,不同的是,forEachOrdered是有顺序保证的,也就是对 Stream 中元素按插入时的顺序进行消费。为什么这么说呢,当开启并行的时候,forEach和 forEachOrdered的效果就不一样了。
java
Stream<String> a = Stream.of("a", "b", "c");
a.parallel().forEach(e -> System.out.println(e.toUpperCase()));当使用上面的代码时,输出的结果可能是 B、A、C 或者 A、C、B或者A、B、C,而使用下面的代码,则每次都是 A、 B、C
java
Stream<String> a = Stream.of("a", "b", "c");
a.parallel().forEachOrdered(e -> System.out.println(e.toUpperCase()));limit
获取前 n 条数据,类似于 MySQL 的limit,只不过只能接收一个参数,就是数据条数。
java
private static void limit() {
Stream<String> a = Stream.of("a", "b", "c");
a.limit(2).forEach(e -> System.out.println(e));
}上述代码打印的结果是 a、b。
skip
跳过前 n 条数据,例如下面代码,返回结果是 c。
java
private static void skip() {
Stream<String> a = Stream.of("a", "b", "c");
a.skip(2).forEach(e -> System.out.println(e));
}distinct
元素去重,例如下面方法返回元素是 a、b、c,将重复的 b 只保留了一个。
java
private static void distinct() {
Stream<String> a = Stream.of("a", "b", "c", "b");
a.distinct().forEach(e -> System.out.println(e));
}sorted
有两个重载,一个无参数,另外一个有个 Comparator类型的参数。
无参类型的按照自然顺序进行排序,只适合比较单纯的元素,比如数字、字母等。
private static void sorted() { Stream<String> a = Stream.of("a", "c", "b"); a.sorted().forEach(e->System.out.println(e));}有参数的需要自定义排序规则,例如下面这个方法,按照第二个字母的大小顺序排序,最后输出的结果是 a1、b3、c6。
java
private static void sortedWithComparator() {
Stream<String> a = Stream.of("a1", "c6", "b3");
a.sorted((x, y) -> Integer.parseInt(x.substring(1)) > Integer.parseInt(y.substring(1)) ? 1 : -1).forEach(e -> System.out.println(e));
}为了更好的说明接下来的几个 API ,我模拟了几条项目中经常用到的类似数据,10条用户信息。
java
private static List<User> getUserData() {
Random random = new Random();
List<User> users = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
User user = new User();
user.setUserId(i);
user.setUserName(String.format("古时的风筝 %s 号", i));
user.setAge(random.nextInt(100));
user.setGender(i % 2);
user.setPhone("18812021111");
user.setAddress("无");
users.add(user);
}
return users;
}filter
用于条件筛选过滤,筛选出符合条件的数据。例如下面这个方法,筛选出性别为 0,年龄大于 50 的记录。
java
private static void filter() {
List<User> users = getUserData();
Stream<User> stream = users.stream();
stream.filter(user -> user.getGender().equals(0) && user.getAge() > 50).forEach(e -> System.out.println(e));
/** *等同于下面这种形式 匿名内部类 */
// stream.filter(new Predicate<User>() {
// @Override
// public boolean test (User user){
// return user.getGender().equals(0) && user.getAge() > 50;
// }
// }).forEach(e->System.out.println(e));
}map
map方法的接口方法声明如下,接受一个 Function函数式接口,把它翻译成映射最合适了,通过原始数据元素,映射出新的类型。
java
<R> Stream<R> map(Function<? super T, ? extends R> mapper);而 Function的声明是这样的,观察 apply方法,接受一个 T 型参数,返回一个 R 型参数。用于将一个类型转换成另外一个类型正合适,这也是 map的初衷所在,用于改变当前元素的类型,例如将 Integer 转为 String类型,将 DAO 实体类型,转换为 DTO 实例类型。
当然了,T 和 R 的类型也可以一样,这样的话,就和 peek方法没什么不同了。
java
@FunctionalInterfacepublic interface Function<T, R> { /** * Applies this function to the given argument. * * @param t the function argument * @return the function result */ R apply(T t);}例如下面这个方法,应该是业务系统的常用需求,将 User 转换为 API 输出的数据格式。
java
private static void map() {
List<User> users = getUserData();
Stream<User> stream = users.stream();
List<UserDto> userDtos = stream.map(user -> dao2Dto(user)).collect(Collectors.toList());
}
private static UserDto dao2Dto(User user) {
UserDto dto = new UserDto();
BeanUtils.copyProperties(user, dto);
//其他额外处理
return dto;
}mapToInt
将元素转换成 int 类型,在 map方法的基础上进行封装。
mapToLong
将元素转换成 Long 类型,在 map方法的基础上进行封装。
mapToDouble
将元素转换成 Double 类型,在 map方法的基础上进行封装。
flatMap
这是用在一些比较特别的场景下,当你的 Stream 是以下这几种结构的时候,需要用到 flatMap方法,用于将原有二维结构扁平化。
Stream<String[]>Stream<Set<String>>Stream<List<String>>
以上这三类结构,通过 flatMap方法,可以将结果转化为 Stream<String>这种形式,方便之后的其他操作。
比如下面这个方法,将List<List<User>>扁平处理,然后再使用 map或其他方法进行操作。
java
private static void flatMap() {
List<User> users = getUserData();
List<User> users1 = getUserData();
List<List<User>> userList = new ArrayList<>();
userList.add(users);
userList.add(users1);
Stream<List<User>> stream = userList.stream();
List<UserDto> userDtos = stream.flatMap(subUserList -> subUserList.stream()).map(user -> dao2Dto(user)).collect(Collectors.toList());
}flatMapToInt
用法参考 flatMap,将元素扁平为 int 类型,在 flatMap方法的基础上进行封装。
flatMapToLong
用法参考 flatMap,将元素扁平为 Long 类型,在 flatMap方法的基础上进行封装。
flatMapToDouble
用法参考 flatMap,将元素扁平为 Double 类型,在 flatMap方法的基础上进行封装。
collection
在进行了一系列操作之后,我们最终的结果大多数时候并不是为了获取 Stream 类型的数据,而是要把结果变为 List、Map 这样的常用数据结构,而 collection就是为了实现这个目的。
就拿 map 方法的那个例子说明,将对象类型进行转换后,最终我们需要的结果集是一个 List<UserDto >类型的,使用 collect方法将 Stream 转换为我们需要的类型。
下面是 collect接口方法的定义:
java
<R, A> R collect(Collector<? super T, A, R> collector);下面这个例子演示了将一个简单的 Integer Stream 过滤出大于 7 的值,然后转换成 List<Integer>集合,用的是 Collectors.toList()这个收集器。
java
private static void collect() {
Stream<Integer> integerStream = Stream.of(1, 2, 5, 7, 8, 12, 33);
List<Integer> list = integerStream.filter(s -> s.intValue() > 7).collect(Collectors.toList());
}很多同学表示看不太懂这个 Collector是怎么一个意思,来,我们看下面这段代码,这是 collect的另一个重载方法,你可以理解为它的参数是按顺序执行的,这样就清楚了,这就是个 ArrayList 从创建到调用 addAll方法的一个过程。
java
private static void collect() {
Stream<Integer> integerStream = Stream.of(1, 2, 5, 7, 8, 12, 33);
List<Integer> list = integerStream.filter(s -> s.intValue() > 7).collect(ArrayList::new, ArrayList::add, ArrayList::addAll);
}我们在自定义 Collector的时候其实也是这个逻辑,不过我们根本不用自定义, Collectors已经为我们提供了很多拿来即用的收集器。比如我们经常用到Collectors.toList()、Collectors.toSet()、Collectors.toMap()。另外还有比如Collectors.groupingBy()用来分组,比如下面这个例子,按照 userId 字段分组,返回以 userId 为key,List<User> 为value 的 Map,或者返回每个 key 的个数。
java
// 返回 userId:
List<User> Map<String, List<User>>map =user.stream().collect(Collectors.groupingBy(User::getUserId));
// 返回 userId:每组个数
Map<String, Long> map = user.stream().collect(Collectors.groupingBy(User::getUserId, Collectors.counting()));toArray
collection是返回列表、map 等,toArray是返回数组,有两个重载,一个空参数,返回的是 Object[]。
另一个接收一个 IntFunction<R>类型参数。
java
@FunctionalInterfacepublic interface IntFunction<R> { /** * Applies this function to the given argument. * * @param value the function argument * @return the function result */ R apply(int value);}比如像下面这样使用,参数是 User[]::new也就是new 一个 User 数组,长度为最后的 Stream 长度。
java
private static void toArray() {
List<User> users = getUserData();
Stream<User> stream = users.stream();
User[] userArray = stream.filter(user -> user.getGender().equals(0) && user.getAge() > 50).toArray(User[]::new);
}reduce
它的作用是每次计算的时候都用到上一次的计算结果,比如求和操作,前两个数的和加上第三个数的和,再加上第四个数,一直加到最后一个数位置,最后返回结果,就是 reduce的工作过程。
java
private static void reduce() {
Stream<Integer> integerStream = Stream.of(1, 2, 5, 7, 8, 12, 33);
Integer sum = integerStream.reduce(0, (x, y) -> x + y);
System.out.println(sum);
}另外 Collectors好多方法都用到了 reduce,比如 groupingBy、minBy、maxBy等等。