主题
Logstash 介绍
概述
官方文档:https://www.elastic.co/guide/en/logstash/7.17/introduction.html
Logstash 是一款开源数据收集引擎,具备实时流水线功能。Logstash 可以动态地整合来自不同数据源的数据,并将其规范化到您选择的目标位置。它能够清理并简化您的所有数据,以适应各种高级下游分析和可视化用例。
虽然 Logstash 最初推动了日志收集领域的创新,但它的功能远不止于此。任何类型的事件都可以通过丰富的输入、过滤和输出插件进行丰富和转换,而许多原生编解码器则进一步简化了数据采集流程。Logstash 通过利用更大规模和更多样化的数据,加速您的洞察。
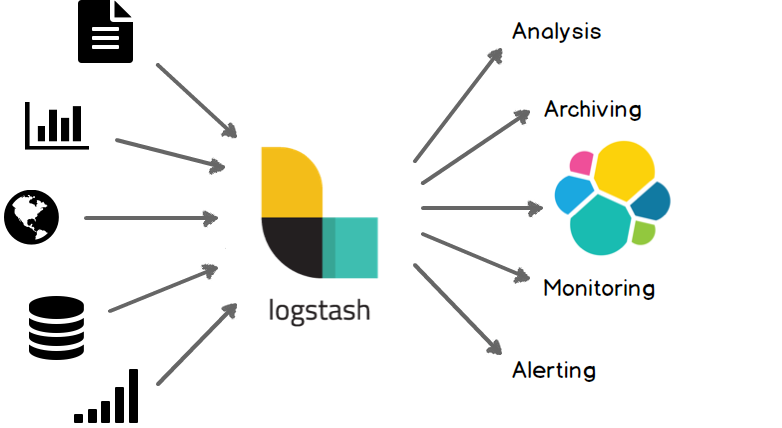
Logstash 的主要特点包括:
多输入源:Logstash 支持多种类型的输入数据,包括日志文件、系统消息队列、数据库等。
数据处理:Logstash 可以对数据进行各种转换和处理,如过滤、解析、格式化等。
多输出目标:Logstash 可以将数据发送到各种目标,如 Elasticsearch、Kafka、邮件通知等。
插件机制:Logstash 提供了丰富的插件,可以方便地扩展其功能。
与 Elasticsearch 和 Kibana 的集成:Logstash 是 Elastic Stack(前称 ELK Stack)的一部分,与 Elasticsearch 和 Kibana 有很好的集成,可以方便地进行数据搜索、存储和可视化。
工作原理
参考文档:https://www.elastic.co/guide/en/logstash/7.17/pipeline.html
Logstash 的工作原理可以分为三个主要步骤:输入(Input)、过滤(Filter)和输出(Output)。
- 输入(Input):Logstash 支持多种类型的输入数据,包括日志文件、系统消息队列、数据库等。在配置文件中,你可以指定一个或多个输入源。
- 过滤(Filter):输入数据被收集后,Logstash 可以对数据进行各种转换和处理。例如,你可以使用 grok 插件来解析非结构化的日志数据,将其转换为结构化的数据。你也可以使用 mutate 插件来修改数据,如添加新的字段、删除字段、更改字段的值等。
- 输出(Output):处理后的数据可以被发送到一个或多个目标。Logstash 支持多种类型的输出目标,包括 Elasticsearch、Kafka、邮件通知等。
这三个步骤是在 Logstash 的事件处理管道中顺序执行的。每个事件(例如,一行日志数据)都会经过输入、过滤和输出这三个步骤。在过滤阶段,如果一个事件被过滤器丢弃,那么它将不会被发送到输出目标。

工作模型
参考文档:https://www.elastic.co/guide/en/logstash/7.17/execution-model.html
每个 Input 启动一个线程:Logstash 会为每个输入插件启动一个线程,这些线程并行运行,从各自的数据源获取数据。
数据写入队列:输入插件获取的数据会被写入一个队列。默认情况下,这是一个存储在内存中的有界队列,如果 Logstash 意外停止,队列中的数据会丢失。为了防止数据丢失,Logstash 提供了两个特性:
- Persistent Queues:这个特性会将队列存储在磁盘上,即使 Logstash 意外停止,队列中的数据也不会丢失。
- Dead Letter Queues:这个特性会保存无法处理的事件。需要注意的是,这个特性只支持 Elasticsearch 作为输出源。
多个 Pipeline Worker 处理数据:Logstash 会启动多个 Pipeline Worker,每个 Worker 会从队列中取出一批数据,然后执行过滤器和输出插件。Worker 的数量和每次处理的数据量可以在配置文件中设置。
下载安装
...