主题
倒排索引
倒排索引(Inverted index) 倒排索引是一种将词项映射到文档的数据结构,这与传统关系型数据库的工作方式不同。你可以把倒排索引当做面向词项的而不是面向文档的数据结构。(倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index))
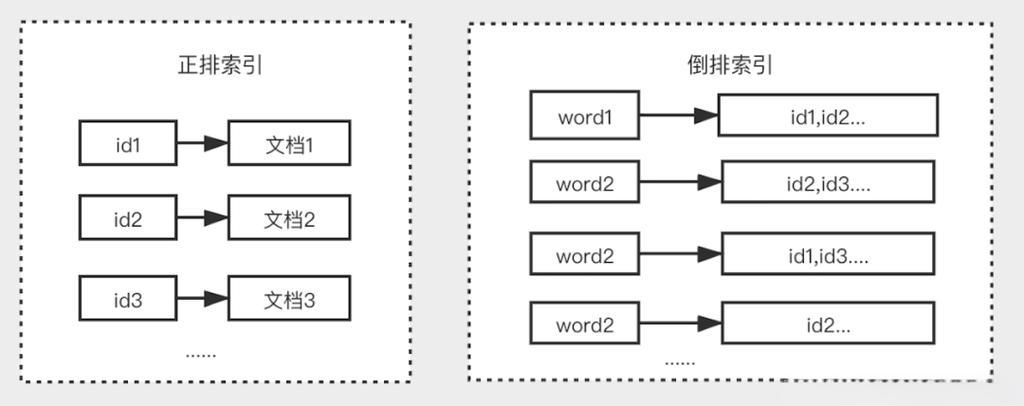
- 正排索引:是以文档对象的唯一 ID 作为索引,以文档内容作为记录的结构。
- 倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。
例子
有以下文档:
| DocId | Doc |
|---|---|
| 1 | 谷歌地图之父跳槽 Facebook |
| 2 | 谷歌地图之父加盟 Facebook |
| 3 | 谷歌地图创始人拉斯离开谷歌加盟 Facebook |
| 4 | 谷歌地图之父跳槽 Facebook 与 Wave 项目取消有关 |
| 5 | 谷歌地图之父拉斯加盟社交网站 Facebook |
对文档进行分词之后,得到以下倒排索引。
| WordId | Word | DocIds |
|---|---|---|
| 1 | 谷歌 | 1, 2, 3, 4, 5 |
| 2 | 地图 | 1, 2, 3, 4, 5 |
| 3 | 之父 | 1, 2, 4, 5 |
| 4 | 跳槽 | 1, 4 |
| 5 | 1, 2, 3, 4, 5 | |
| 6 | 加盟 | 2, 3, 5 |
| 7 | 创始人 | 3 |
| 8 | 拉斯 | 3, 5 |
| 9 | 离开 | 3 |
| 10 | 与 | 4 |
| .. | .. | .. |
在搜索引擎中应用
一般来说,倒排索引常在搜索引擎内做全文检索使用,其不同于关系数据库中的B+Tree和B-Tree 。B+Tree和B-Tree 索引是从树根往下按左前缀方式来递减缩小查询范围,而倒排索引的过程可以大致分四个步骤:分词、取出相关DocId、计算权重并重新排序、展示高相关度的记录。
首先,对用户输入的内容做分词,找出关键词;然后,通过多个关键词对应的倒排索引,取出所有相关的DocId;接下来,将多个关键词设计索引ID做交集后,再根据关键词在每个文档的出现次数及频率,以此计算出每条结果的权重,进而给列表排序,并实现基于查询匹配度的评分;然后就可以根据匹配评分来降序排序,列出相关度高的记录。
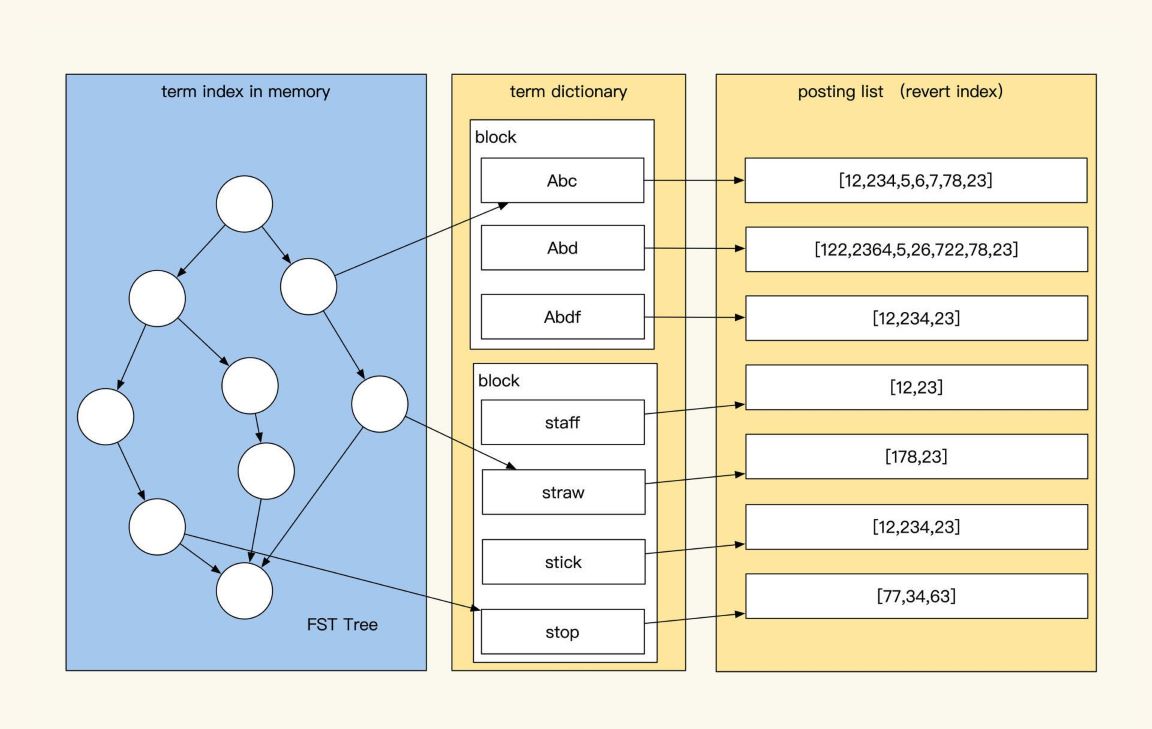
如上图,Elasticsearch集群的索引保存在Lucene的segment文件中,segment文件格式相关信息你可以参考 segment格式,其中包括行存、列存、倒排索引。
为了节省空间和提高查询效率,Lucene对关键字倒排索引做了大量优化,segment主要保存了三种索引:
- Term Index(单词词典索引):用于关键词(Term)快速搜索,Term index是基础Trie树改进的FST(Finite State Transducer有限状态传感器,占用内存少)实现的二级索引。平时这个树会放在内存中,用于减少磁盘IO加快Term查找速度,检索时会通过FST快速找到Term Dictionary对应的词典文件block。
- Term Dictionary(单词词典):单词词典索引中保存的是单词(Term)与Posting List的关系,而这个单词词典数据会按block在磁盘中排序压缩保存,相比B-Tree更节省空间,其中保存了单词的前缀后缀,可以用于近似词及相似词查询,通过这个词典可以找到相关的倒排索引列表位置。
- Posting List(倒排列表):倒排列表记录了关键词Term出现的文档ID,以及其所在文档中位置、偏移、词频信息,这是我们查找的最终文档列表,我们拿到这些就可以拿去排序合并了。 一条日志在入库时,它的具体内容并不会被真实保存在倒排索引中。
在日志入库之前,会先进行分词,过滤掉无用符号等分隔词,找出文档中每个关键词(Term)在文档中的位置及频率权重;然后,将这些关键词保存在Term Index以及Term Dictionary内;最后,将每个关键词对应的文档ID和权重、位置等信息排序合并到Posting List中进行保存。通过上述三个结构就实现了一个优化磁盘IO的倒排索引。
而查询时,Elasticsearch会将用户输入的关键字通过分词解析出来,在内存中的Term Index单词索引查找到对应Term Dictionary字典的索引所在磁盘的block。接着,由Term Dictionary找到对关键词对应的所有相关文档DocId及权重,并根据保存的信息和权重算法对查询结果进行排序返回结果。