主题
什么是负载均衡?
例子
先举个例子吧。以超市收银为例,假设现在只有一个窗口、一个收银员:
- 一般情况下,收银员平均2分钟服务一位顾客,10分钟可以服务5位顾客;
- 到周末高峰期时,收银员加快收银,平均1分钟服务一位顾客,10分钟最多服务10位顾客,也就是说一个顾客最多等待10分钟;
- 逢年过节,顾客数量激增,一下增加到30位顾客,如果仍然只有一个窗口和一个收银员,那么所有顾客就只能排队等候了,一个顾客最多需要等待30分钟。这样购物体验,就非常差了。
那有没有解决办法呢?
当然有。那就是新开一个收银窗口,每个收银窗口服务15个顾客,这样最长等待时间从30分钟缩短到15分钟。但如果,这两个窗口的排队顾客数严重不均衡,比如一个窗口有5个顾客排队,另一个窗口却有25个顾客排队,就不能最大化地提升顾客的购物体验。
所以,尽可能使得每个收银窗口排队的顾客一样多,才能最大程度地减少顾客的最长排队时间,提高用户体验。
看完这个例子,你是不是想到了一句话“不患寡,而患不均”?这,其实就是负载均衡的基本原理。
分类
通常情况下,负载均衡可以分为两种:
请求负载均衡
分布式系统中,服务请求的负载均衡是指,当处理大量用户请求时,请求应尽量均衡地分配到多台服务器进行处理,每台服务器处理其中一部分而不是所有的用户请求,以完成高并发的请求处理,避免因单机处理能力的上限,导致系统崩溃而无法提供服务的问题。
数据负载均衡
即将用户更新的数据分发到不同的存储服务器
服务请求的负载均衡方法
通常情况下,计算机领域中,在不同层有不同的负载均衡方法。比如,从网络层的角度,通常有基于DNS、IP报文等的负载均衡方法;在中间件层(也就是我们专栏主要讲的分布式系统层),常见的负载均衡策略主要包括轮询策略、随机策略、哈希和一致性哈希等策略。
DNS
待补充.....
中间件层均衡策略
轮询策略
轮询策略是一种实现简单,却很常用的负载均衡策略,核心思想是服务器轮流处理用户请求,以尽可能使每个服务器处理的请求数相同。生活中也有很多类似的场景,比如,学校宿舍里,学生每周轮流打扫卫生,就是一个典型的轮询策略。
顺序轮询
假设有6个请求,编号为请求1~6,有3台服务器可以处理请求,编号为服务器1~3,如果采用顺序轮询策略,则会按照服务器1、2、3的顺序轮流进行请求。
如表所示,将6个请求当成6个步骤:
| 步骤 | 请求编号 | 服务器编号 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 3 |
| 4 | 4 | 1 |
| 5 | 5 | 2 |
| 6 | 6 | 3 |
- 请求1由服务器1处理;
- 请求2由服务器2进行处理。
- 以此类推,直到处理完这6个请求。
最终的处理结果是,服务器1处理请求1和请求4,服务器2处理请求2和请求5,服务器3处理请求3和请求6。
加权轮询 加权轮询为每个服务器设置了优先级,每次请求过来时会挑选优先级最高的服务器进行处理。比如服务器1~3分配了优先级{4,1,1},这6个请求到来时,还当成6个步骤,如表所示。
| 步骤 | 请求编号 | 各服务器优先级 | 服务器编号 |
|---|---|---|---|
| 1 | 1 | 4,1,1 | 1 |
| 2 | 2 | 3,1,1 | 1 |
| 3 | 3 | 2,1,1 | 1 |
| 4 | 4 | 1,1,1 | 1 |
| 5 | 5 | 0,1,1 | 2 |
| 6 | 6 | 0,0,1 | 3 |
- 请求1由优先级最高的服务器1处理,服务器1的优先级相应减1,此时各服务器优先级为{3,1,1};
- 请求2由目前优先级最高的服务器1进行处理,服务器1优先级相应减1,此时各服务器优先级为{2,1,1}。
- 以此类推,直到处理完这6个请求。每个请求处理完后,相应服务器的优先级会减1。
最终的处理结果是,服务器1处理请求1~4,服务器2处理请求5,服务器3会处理请求6。
以上就是顺序轮询和加权轮询的核心原理了。轮询策略的应用比较广泛,比如Nginx默认的负载均衡策略就是一种改进的加权轮询策略。
优点
实现简单,且对于请求所需开销差不多时,负载均衡效果比较明显,同时加权轮询策略还考虑了服务器节点的异构性,即可以让性能更好的服务器具有更高的优先级,从而可以处理更多的请求,使得分布更加均衡。
缺点
每次请求到达的目的节点不确定,不适用于有状态请求的场景。并且,轮询策略主要强调请求数的均衡性,所以不适用于处理请求所需开销不同的场景。
随机策略
随机策略也比较容易理解,指的就是当用户请求到来时,会随机发到某个服务节点进行处理,可以采用随机函数实现。这里,随机函数的作用就是,让请求尽可能分散到不同节点,防止所有请求放到同一节点或少量几个节点上。
如图所示,假设有5台服务器Server 1~5可以处理用户请求,每次请求到来时,都会先调用一个随机函数来计算出处理节点。这里,随机函数的结果只能是{1,2,3,4,5}这五个值,然后再根据计算结果分发到相应的服务器进行处理。比如,图中随机函数计算结果为2,因此该请求会由Server2处理。
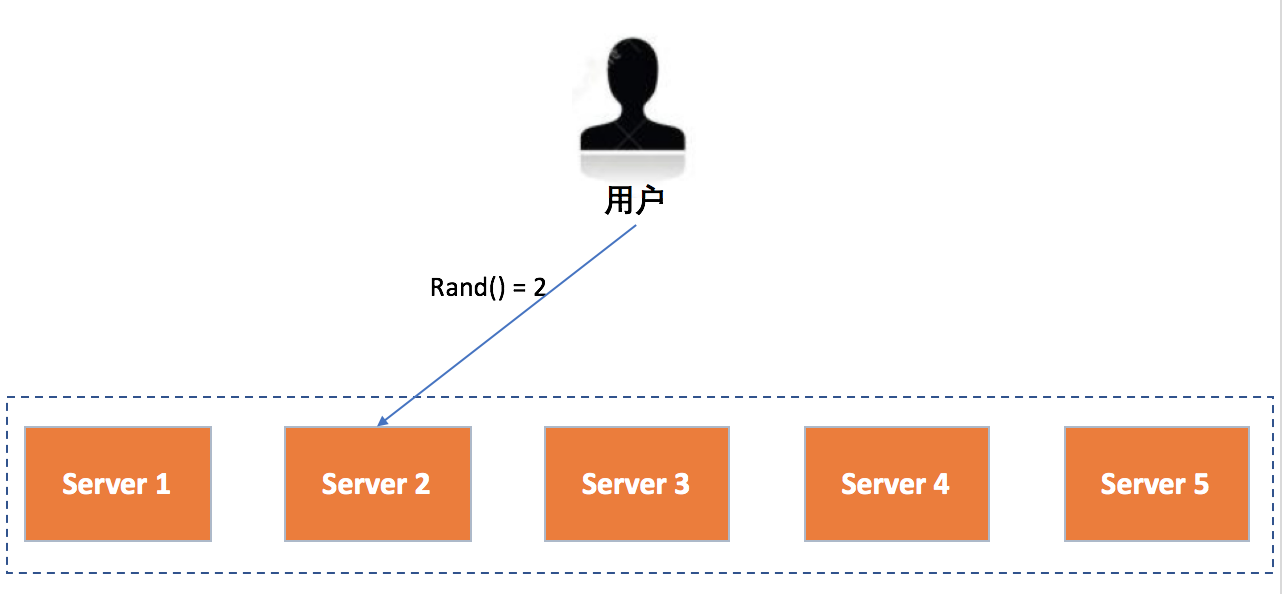
这种方式的优点是,实现简单,但缺点也很明显,与轮询策略一样,每次请求到达的目的节点不确定,不适用于有状态的场景,而且没有考虑到处理请求所需开销。除此之外,随机策略也没有考虑服务器节点的异构性,即性能差距较大的服务器可能处理的请求差不多。
因此,随机策略适用于,集群中服务器节点处理能力相差不大,用户请求所需资源比较接近的场景。
哈希和一致性哈希策略
无论是轮询还是随机策略,对于一个客户端的多次请求,每次落到的服务器很大可能是不同的,如果这是一台缓存服务器,就会对缓存同步带来很大挑战。尤其是系统繁忙时,主从延迟带来的同步缓慢,可能会造成同一客户端两次访问得到不同的结果。解决方案就是,利用哈希算法定位到对应的服务器。
优点
哈希函数设置合理的话,负载会比较均衡。而且,相同key的请求会落在同一个服务节点上,可以用于有状态请求的场景。除此之外,带虚拟节点的一致性哈希策略还可以解决服务器节点异构的问题。
缺点
当某个节点出现故障时,采用哈希策略会出现数据大规模迁移的情况,采用一致性哈希策略可能会造成一定的数据倾斜问题。同样的,这两种策略也没考虑请求开销不同造成的不均衡问题。
总结
| 策略 | 优点 | 缺点 | 适用场景 | 案例 |
|---|---|---|---|---|
| 轮询策略 | 实现简单,负载均衡效果均匀 | 不考虑服务器性能差异,可能导致低性能节点过载 | 用户请求资源需求接近,无状态请求场景 | Nginx |
| 随机策略 | 实现简单,能避免固定请求模式导致的均衡失衡 | 随机性较高,可能导致短期内负载分布不均 | 节点性能差异较小的场景 | Dubbo |
| 哈希和一致性哈希策略 | 能根据请求特性分配资源,适合数据缓存等场景 | 难以处理动态扩展节点,需额外实现虚拟节点来提升均衡性 | 数据缓存、分布式存储等需要根据请求分布的场景 | Redis、Memcached |
| IP哈希策略 | 能将同一客户端的请求固定分配到同一节点,便于会话保持 | 节点变更时可能导致负载不均,扩展性较差 | 需要保持会话或请求来源的场景 | CDN、负载均衡设备 |