主题
爬虫: 国家统计局国内生产总值
前置准备
确认请求参数
进入 国家统计局 网站, 检查点击触发的查询事件, 抓包获取请求数据的参数。
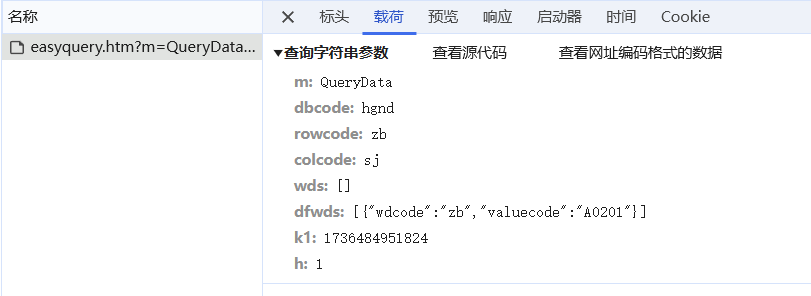
监听请求后可知 URL 为 https://data.stats.gov.cn/easyquery,并构造请求参数字典 params,包含 m、dbcode、rowcode、colcode、wds、dfwds、k1 等参数。
其中重要的是 "dfwds": '[{"wdcode":"zb","valuecode":"A0201"}]' valuecode 为具体项目的唯一标识。
导入python相关库
- pandas:用于数据处理和保存为 CSV 文件。
- requests:用于发送 HTTP 请求,获取数据。
- time:用于获取当前时间戳,生成请求参数中的 k1 值。
代码
python
import pandas as pd
import requests
import time
def fetch_data():
# 设置请求的头部信息,模拟浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Referer": "https://data.stats.gov.cn/easyquery.htm?cn=C01"
}
# 构造请求的 URL 和参数
url = "https://data.stats.gov.cn/easyquery.htm?cn=C01"
params = {
"m": "QueryData", # 数据查询
"dbcode": "hgnd", # 数据库代码(年度数据库为 hgnd)
"rowcode": "zb", # 行代码
"colcode": "sj", # 列代码
"wds": "[]", # 查询条件
"dfwds": '[{"wdcode":"zb","valuecode":"A0201"}]', # 指标代码 A0201 (国内生产总值指数)
"k1": str(int(round(time.time() * 1000))),
"h": 1
}
# 建立 Session
session = requests.session()
# Http请求
response = session.get(url, params=params, headers=headers)
# 打印响应的文本内容
# print(response.text)
# 检查请求状态
if response.status_code != 200:
print(f"请求失败,状态码: {response.status_code}")
return None
# 返回 JSON 数据
return response.json()
# 循环检查 wdnodes 的数组长度是否为 20
while True:
print("开始执行脚本...")
data = fetch_data()
if data is None:
print("数据获取失败,重试中...")
time.sleep(2) # 等待 2 秒后重试
continue
# 检查 wdnodes 的长度
wdnodes = data.get("returndata", {}).get("wdnodes", [])
col_headers = wdnodes[0].get("nodes", [])
# 数据长度符合要求,进行数据处理
print("开始处理数据...")
break
# 提取 `wdnodes` 中的第一列(名称)和列头信息
first_col = [node.get("cname", "") for node in wdnodes[0].get("nodes", [])]
col_headers = [node.get("cname", "") for node in wdnodes[1].get("nodes", [])]
# 提取 `datanodes` 数据
datanodes = data.get("returndata", {}).get("datanodes", [])
# 根据 `datanodes` 和列头长度组织数据
rows = len(first_col) # 行数
cols = len(col_headers) # 列数
# 创建一个空列表用于存储结果
result = [["" for _ in range(cols + 1)] for _ in range(rows)]
# 填充第一列(名称)
for i in range(rows):
result[i][0] = first_col[i]
# 填充数据列
for node in datanodes:
row_code = node.get("wds", [])[0].get("valuecode", "") # 行代码
col_code = node.get("wds", [])[1].get("valuecode", "") # 列代码
value = node.get("data", {}).get("data", "")
# 根据代码找到对应的行和列索引
row_index = next((i for i, n in enumerate(wdnodes[0]["nodes"]) if n.get("code") == row_code), None)
col_index = next((j for j, n in enumerate(wdnodes[1]["nodes"]) if n.get("code") == col_code), None)
if row_index is not None and col_index is not None:
# 四舍五入保留整数
try:
value = round(float(value)) if value != "" else ""
except ValueError:
value = "" # 如果无法转换为数值,置为空
result[row_index][col_index + 1] = value
# 转换为 DataFrame 并添加列名
df = pd.DataFrame(result, columns=["名称"] + col_headers)
# 保存为 CSV 文件
output_file = "国内生产总值指数 - 统计数据.csv"
df.to_csv(output_file, index=False, encoding="utf-8-sig")
print(f"数据已保存到 {output_file}")效果图
