主题
语音识别 Qwen-Audio
Qwen-Audio 多任务语音模型
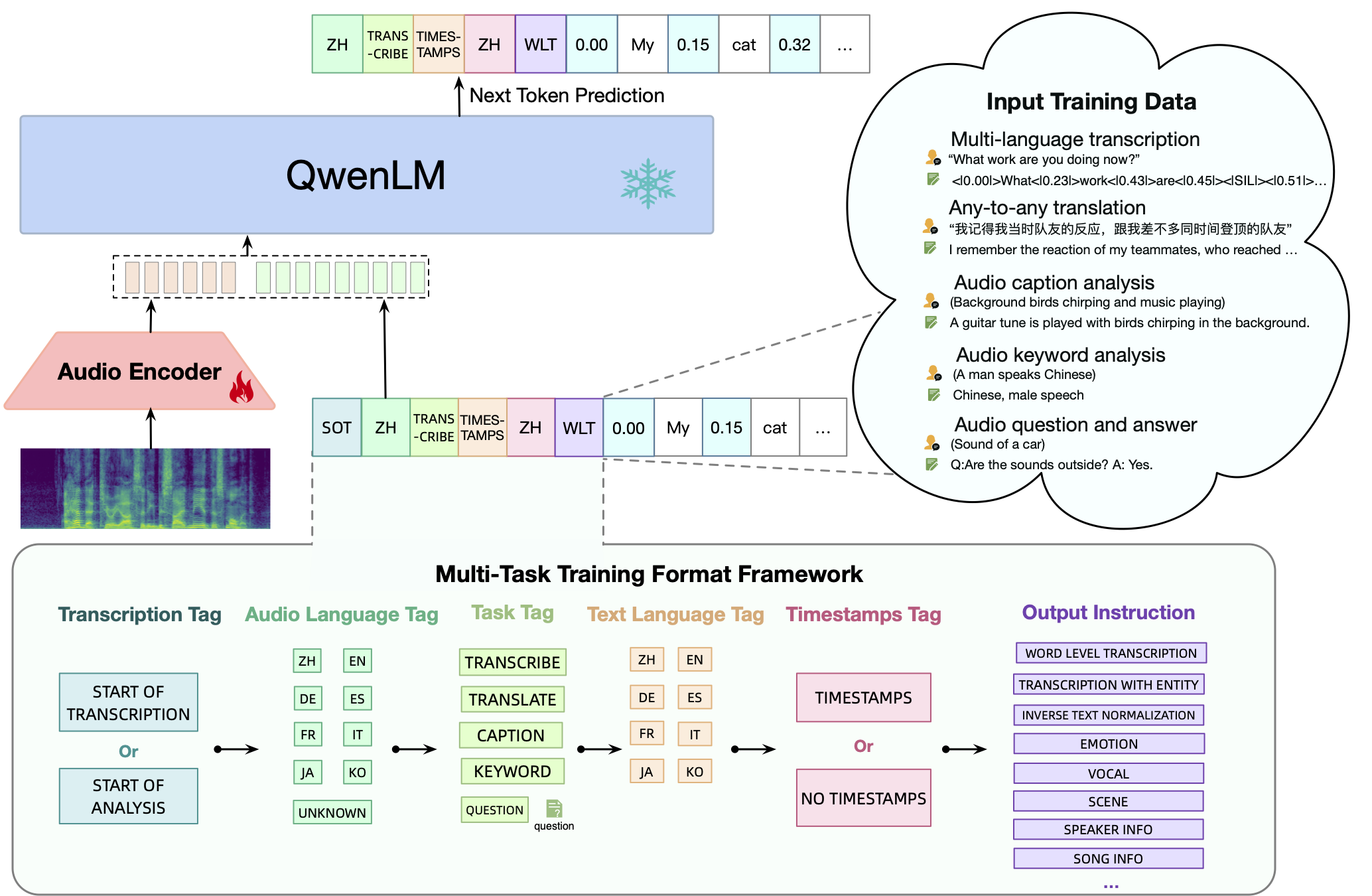
Qwen-Audio是阿里云于2023年11月30日开源的一款面向语音任务的多功能大模型。它基于OpenAI的Whisper Large-v2模型和Qwen 7B大语言模型进行开发,具有多种语音处理能力。该模型的主要特点包括:
- 多语言语音识别:能够识别并转录多种语言的语音内容。
- 语音翻译:具备将语音内容从一种语言翻译到另一种语言的能力。
- 语音场景分析:能够分析语音中的环境信息和背景声音。
- 基于语音的理解和推理:不仅转录语音,还能理解语音内容并进行逻辑推理。
- 语音编辑功能:提供编辑和修改语音记录的工具。
这些特性使Qwen-Audio成为一个处理各类语音任务的强大工具。
演示界面:https://qwen-audio.github.io/Qwen-Audio/
阿里云开源了两个语音处理模型:Qwen-Audio 和 Qwen-Audio-Chat,它们分别针对不同的应用场景。Qwen-Audio 主要用于处理特定的语音处理任务,例如语音识别,而 Qwen-Audio-Chat 则更适用于基于语音的多轮对话任务。关于 Qwen-Audio 模型,其在语音识别方面的主要特性包括:
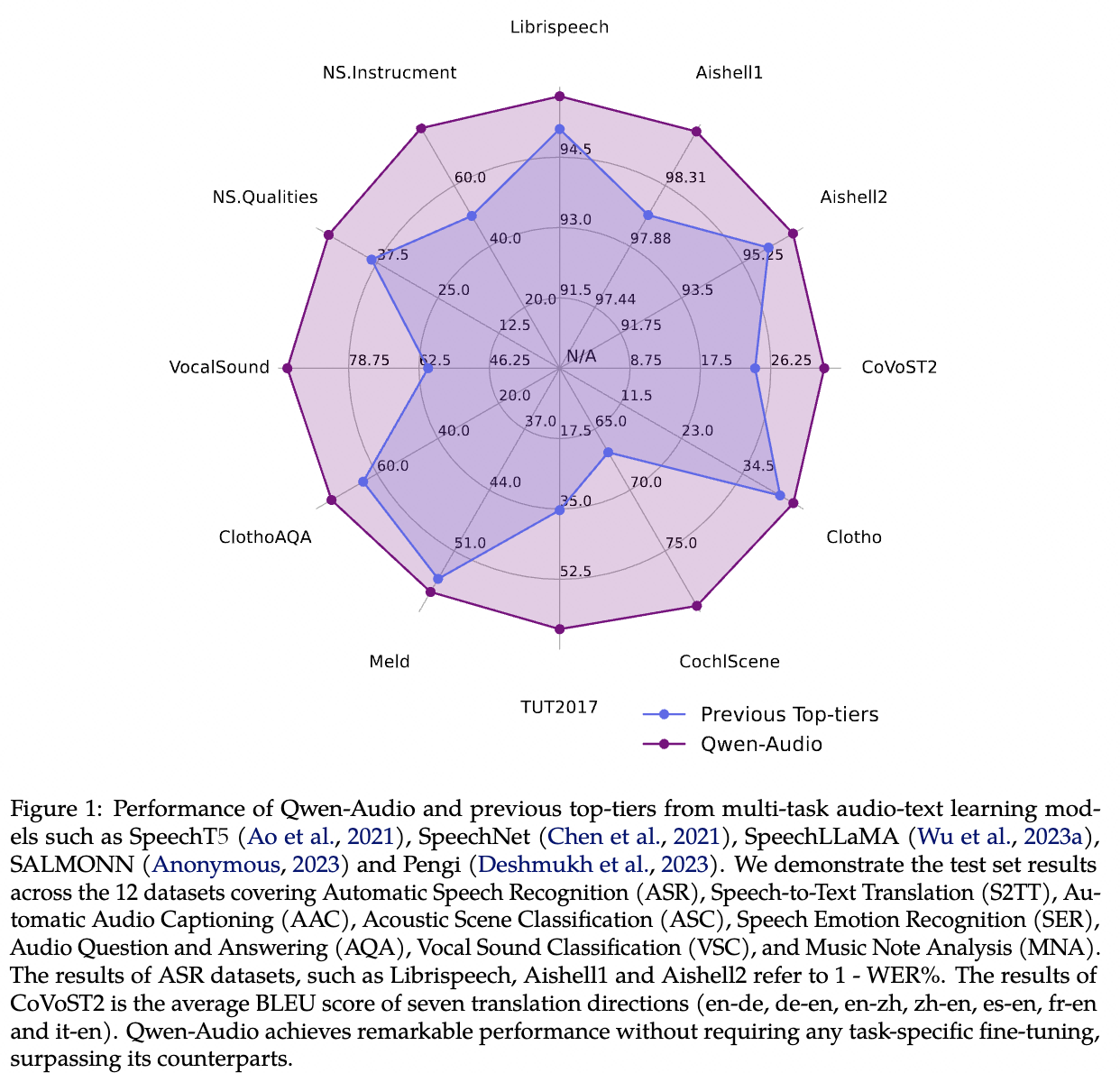
- Librispeech数据集表现:在Librispeech数据集上,Qwen-Audio 展现出了卓越的语音识别性能。
- Aishell1和Aishell2数据集的SOTA成绩:在这两个中文语音数据集上,模型实现了最佳状态(State of the Art, SOTA)的识别结果。
- 支持带词级别时间戳的语音识别:Qwen-Audio 能够在执行语音识别任务的同时,为每个词提供精确的时间戳。
更多的说明:
https://github.com/QwenLM/Qwen-Audio/blob/main/README_CN.md
环境安装与语音识别 (旧版)
framework
Performance
下载代码(需要安装git工具)
# yum install git
git clone https://github.com/QwenLM/Qwen-Audio.git创建 Dockerfile
在 Qwen-Audio 项目根目录下创建一个 Dockerfile:
dockerfile
# 使用轻量级基础镜像
FROM python:3.9-slim
WORKDIR /app
# 复制文件到工作目录
COPY /Qwen-Audio/ .
# 设置阿里云镜像加速
RUN pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 更换为阿里云 Debian 镜像源
RUN echo "deb http://mirrors.aliyun.com/debian/ bookworm main non-free" > /etc/apt/sources.list
RUN echo "deb http://mirrors.aliyun.com/debian/ bookworm-updates main non-free" >> /etc/apt/sources.list
RUN echo "deb http://mirrors.aliyun.com/debian/ bookworm-backports main non-free" >> /etc/apt/sources.list
RUN echo "deb http://mirrors.aliyun.com/debian-security/ bookworm-security main non-free" >> /etc/apt/sources.list
# 更新并安装 FFmpeg
RUN apt-get clean
RUN apt-get update && apt-get install -y ffmpeg
# 安装依赖, 使用阿里云的 PyPI 镜像源
RUN pip install -r requirements.txt
# 安装额外依赖, 有些不在官方镜像内必须的, 但在api.py使用到
RUN pip install flask pydub
# 将 huggingface.co 替换为 hf-mirror.com, 这里的 1.2.3.4 是 hf-mirror.com 的 IP 地址。
RUN echo "1.2.3.4 huggingface.co" >> /etc/hosts
EXPOSE 5000
# 运行 API 服务
CMD ["python", "api.py"]
# 使用Gunicorn提升性能
# RUN pip install gunicorn
# CMD ["gunicorn", "-b", "0.0.0.0:5000", "-w", "4", "api:app"]篇外: 安装ffmpeg
下载地址 https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz
上传至服务器解压
sh
tar -xvf ffmpeg-release-amd64-static.tar.xz在Dockerfile 中添加以下内容
dockerfile
...
# 安装 FFmpeg
# 复制主机上的 FFmpeg 二进制文件到 Docker 容器中
COPY ffmpeg /usr/local/bin/ffmpeg
COPY ffprobe /usr/local/bin/ffprobe
...创建 Python API 代码
创建一个 Python 脚本 api.py (放在Qwen-Audio文件夹内),用于提供 RESTful API 服务。
python
import os
import tempfile
import torch
import logging
from flask import Flask, request, jsonify
from transformers import AutoModelForCausalLM, AutoTokenizer
from pydub import AudioSegment
from pydub.silence import split_on_silence
# 初始化应用
app = Flask(__name__)
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("Qwen-Audio-API")
# 全局模型变量
model = None
tokenizer = None
def initialize_model():
"""初始化语音识别模型"""
global model, tokenizer
if model is None or tokenizer is None:
try:
logger.info("开始加载 Qwen-Audio 模型...")
model_name = "Qwen/Qwen-Audio-Chat"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
trust_remote_code=True
).eval()
logger.info("模型加载成功!设备: %s", model.device)
# 执行一次预热推理
warm_up_model()
except Exception as e:
logger.error("模型初始化失败: %s", str(e))
raise RuntimeError(f"模型初始化失败: {str(e)}")
def warm_up_model():
"""预热模型,确保首次请求响应快速"""
try:
logger.info("执行模型预热...")
with torch.no_grad():
query = tokenizer.from_list_format([
{'audio': None},
{'text': "测试预热"},
])
_, _ = model.chat(tokenizer, query=query, history=None)
logger.info("模型预热完成")
except Exception as e:
logger.warning("模型预热失败: %s", str(e))
def split_long_audio(audio_path, chunk_length=30):
"""
分割长音频为30秒的片段
参数:
audio_path: 音频文件路径
chunk_length: 每个片段的时长(秒)
返回:
分段后的音频文件路径列表
"""
try:
logger.info("开始分割长音频: %s", audio_path)
# 加载音频文件
audio = AudioSegment.from_file(audio_path)
duration = len(audio) / 1000 # 转换为秒
# 如果音频短于分段长度,直接返回
if duration <= chunk_length:
return [audio_path]
# 基于静音分割更自然
chunks = split_on_silence(
audio,
min_silence_len=500, # 0.5秒静音作为分割点
silence_thresh=-40, # 静音阈值 (dBFS)
keep_silence=300 # 保留0.3秒静音
)
# 如果没有检测到静音,按固定时长分割
if not chunks:
logger.info("未检测到静音,使用固定时长分割")
chunks = [audio[i*1000:(i+chunk_length)*1000]
for i in range(0, int(duration)//chunk_length)]
# 保存分段音频
output_files = []
output_dir = tempfile.mkdtemp()
for i, chunk in enumerate(chunks):
chunk_path = os.path.join(output_dir, f"chunk_{i}.wav")
chunk.export(chunk_path, format="wav")
output_files.append(chunk_path)
logger.info("分割完成: %d 个片段", len(output_files))
return output_files
except Exception as e:
logger.error("音频分割失败: %s", str(e))
raise RuntimeError(f"音频分割失败: {str(e)}")
# 在应用启动时初始化模型
initialize_model()
@app.route('/health', methods=['GET'])
def health_check():
"""健康检查端点"""
if model is None or tokenizer is None:
return jsonify({"status": "down", "reason": "model not loaded"}), 503
try:
# 简单模型检查
with torch.no_grad():
query = tokenizer.from_list_format([
{'audio': None},
{'text': "健康检查"},
])
_, _ = model.chat(tokenizer, query=query, history=None)
return jsonify({
"status": "up",
"device": str(model.device),
"torch_version": torch.__version__
})
except Exception as e:
return jsonify({"status": "down", "reason": str(e)}), 500
@app.route('/transcribe', methods=['POST'])
def transcribe_audio():
"""
语音转录API
支持短音频直接转录和长音频自动分割
"""
try:
# 检查文件上传
if 'audio' not in request.files:
return jsonify({"error": "未提供音频文件"}), 400
audio_file = request.files['audio']
text_query = request.form.get('query', '转写这段语音')
enable_segmentation = request.form.get('segmentation', 'true').lower() == 'true'
# 创建临时文件
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as tmp_file:
audio_file.save(tmp_file.name)
audio_path = tmp_file.name
logger.info("收到转录请求: %s, 长度: %.1fs",
audio_file.filename,
AudioSegment.from_file(audio_path).duration_seconds)
# 处理长音频
if enable_segmentation:
segments = split_long_audio(audio_path)
full_text = ""
for segment_path in segments:
segment_text = transcribe_segment(segment_path, text_query)
full_text += segment_text + " "
os.remove(segment_path) # 删除临时分段文件
result_text = full_text.strip()
os.remove(audio_path) # 删除原始临时文件
return jsonify({"text": result_text})
# 直接处理短音频
result_text = transcribe_segment(audio_path, text_query)
os.remove(audio_path) # 删除临时文件
return jsonify({"text": result_text})
except Exception as e:
logger.exception("转录处理失败")
return jsonify({"error": str(e)}), 500
def transcribe_segment(audio_path, text_query):
"""转录单个音频片段"""
try:
# 构建多模态查询
query = tokenizer.from_list_format([
{'audio': audio_path},
{'text': text_query},
])
# 执行语音识别
with torch.no_grad():
response, _ = model.chat(tokenizer, query=query, history=None)
return response
except Exception as e:
logger.error("片段转录失败: %s", str(e))
raise RuntimeError(f"片段转录失败: {str(e)}")
@app.route('/word-timestamp', methods=['POST'])
def word_timestamp():
"""词级时间戳功能"""
try:
data = request.json
if not data or 'word' not in data:
return jsonify({"error": "缺少必要参数"}), 400
word = data['word']
history = data.get('history')
response, history = model.chat(tokenizer, word, history=history)
return jsonify({'response': response, 'history': history})
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
# 生产环境建议使用 Gunicorn
app.run(host='0.0.0.0', port=5000, debug=False)python
import os
import tempfile
import torch
import logging
from flask import Flask, request, jsonify
from transformers import AutoModelForCausalLM, AutoTokenizer
# 初始化应用
app = Flask(__name__)
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("Qwen-7B-API")
# 全局模型变量
model = None
tokenizer = None
# 模型路径
model_path = "/app/Modal"
def initialize_model():
"""初始化模型"""
global model, tokenizer
if model is None or tokenizer is None:
try:
logger.info("开始加载 Qwen-7B 模型...")
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
trust_remote_code=True
).eval()
logger.info("模型加载成功!设备: %s", model.device)
# 执行一次预热推理
warm_up_model()
except Exception as e:
logger.error("模型初始化失败: %s", str(e))
raise RuntimeError(f"模型初始化失败: {str(e)}")
def warm_up_model():
"""预热模型,确保首次请求响应快速"""
try:
logger.info("执行模型预热...")
with torch.no_grad():
query = "测试预热"
inputs = tokenizer(query, return_tensors="pt")
outputs = model.generate(**inputs)
logger.info("模型预热完成")
except Exception as e:
logger.warning("模型预热失败: %s", str(e))
# 在应用启动时初始化模型
initialize_model()
@app.route('/health', methods=['GET'])
def health_check():
"""健康检查端点"""
if model is None or tokenizer is None:
return jsonify({"status": "down", "reason": "model not loaded"}), 503
return jsonify({
"status": "up",
"device": str(model.device),
"torch_version": torch.__version__
})
@app.route('/transcribe', methods=['POST'])
def transcribe_audio():
"""
语音转录API
"""
try:
# 检查文件上传
if 'audio' not in request.files:
return jsonify({"error": "未提供音频文件"}), 400
audio_file = request.files['audio']
text_query = request.form.get('query', '转写这段语音')
# 创建临时文件
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as tmp_file:
audio_file.save(tmp_file.name)
audio_path = tmp_file.name
logger.info("收到转录请求: %s", audio_file.filename)
# 直接处理短音频
result_text = transcribe_segment(audio_path, text_query)
os.remove(audio_path) # 删除临时文件
return jsonify({"text": result_text})
except Exception as e:
logger.exception("转录处理失败")
return jsonify({"error": str(e)}), 500
def transcribe_segment(audio_path, text_query):
"""转录单个音频片段"""
try:
# 构建查询
query = f"{text_query} [AUDIO] {audio_path}"
# 执行语音识别
with torch.no_grad():
inputs = tokenizer(query, return_tensors="pt")
outputs = model.generate(**inputs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
except Exception as e:
logger.error("片段转录失败: %s", str(e))
raise RuntimeError(f"片段转录失败: {str(e)}")
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=False)第一次运行程序会自动下载模型
构建和运行 Docker 镜像
构建 Docker 镜像:
bash
docker build -t qwen-audio-api .使用 Hugging Face 的国内镜像源 https://hf-mirror.com, 运行 Docker 容器:
bash
docker run -d --name qwen-audio-api --gpus all -e HF_ENDPOINT="https://hf-mirror.com" -p 5000:5000 qwen-audio-api整个模型大于为15GB, 下载需要较长时间而且不稳定
篇外: 离线下载模型 (推荐)
访问 huggingface官网 下载模型
找到 Qwen-Audio-Chat 模型,点击 “Files and versions” 下载所有相关文件
Qwen-Audio-Chat (推荐)
将下载好的模型的所有文件放到docker内并修改model_name为模型路径, 如 model_name = "/app/Modal"
Java 应用调用示例
java
package com.switolor.gpt;
import cn.hutool.core.io.FileUtil;
import cn.hutool.http.HttpRequest;
import cn.hutool.http.HttpResponse;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.switolor.common.core.domain.ResultBean;
import com.switolor.common.core.utils.file.FileTools;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
@RestController
@RequestMapping("/audio")
public class QwenAudioClient {
// 从配置文件读取API地址
private static final String API_URL = "http://your-service-ip:5000/transcribe";
private static final Set<String> ALLOWED_EXTENSIONS = Set.of(
".mp3", ".wav", ".ogg", ".flac", ".m4a", ".amr", ".aac"
);
@PostMapping("/upload")
public ResultBean<String> handleAudioUpload(
@RequestParam("audioFile") MultipartFile audioFile) {
File tempFile = null;
try {
// 根据原始文件名获取正确扩展名
String extension = String.format(".%s", FileTools.getExtention(audioFile.getOriginalFilename()));
// 校验是否是音频文件
if (!ALLOWED_EXTENSIONS.contains(extension.toLowerCase())) {
return ResultBean.fail("不支持的文件格式");
}
// 创建临时文件
tempFile = FileUtil.createTempFile("audio-" + System.currentTimeMillis(), extension, true);
audioFile.transferTo(tempFile);
String prompt = "转写这段语音";
// 调用语音识别API
String text = callTranscriptionAPI(tempFile, prompt);
// 识别的内容可以调用文本大语言模型二次优化
// ...
return ResultBean.success(text);
} catch (Exception e) {
return ResultBean.fail("语音识别失败: " + e.getMessage());
} finally {
// 删除临时文件
FileUtil.del(tempFile);
}
}
private String callTranscriptionAPI(File audioFile, String prompt) {
// 构建表单请求
Map<String, Object> formMap = new HashMap<>();
formMap.put("audio", audioFile);
formMap.put("query", prompt);
// 发送HTTP请求
HttpResponse response = HttpRequest.post(API_URL)
.form(formMap) // 自动编码为multipart/form-data
.timeout(30000) // 30秒超时
.execute();
// 检查响应状态
if (!response.isOk()) {
throw new RuntimeException("API响应错误: " + response.getStatus());
}
// 解析JSON响应
JSONObject json = JSONUtil.parseObj(response.body());
if (json.containsKey("error")) {
throw new RuntimeException("API返回错误: " + json.getStr("error"));
}
return json.getStr("text");
}
}篇外: vllm
sh
# Deploy with docker on Linux:
docker run --runtime nvidia --gpus all \
--name my_vllm_container \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model Qwen/Qwen-Audio-Chat
# Load and run the model:
docker exec -it my_vllm_container bash -c "vllm serve Qwen/Qwen-Audio-Chat"
# Call the server using curl:
curl -X POST "http://localhost:8000/v1/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "Qwen/Qwen-Audio-Chat",
"prompt": "Once upon a time,",
"max_tokens": 512,
"temperature": 0.5
}'常见问题
- Q1:为什么长语音只能识别前面的一部分?
Qwen-Audio是基于Whisper的encoder模型训练出来的,Whisper模型单次输入的语音长度,最长只能支持30秒。【要确认?】
- Q2:有没有webui,或者API服务
本地部署的webui(代码库中有一个脚本可以使用): web_demo_audio.py
在线体验版(基于Qwen-Audio-Chat):
魔搭:
https://modelscope.cn/studios/qwen/Qwen-Audio-Chat-Demo/summary
Huggingface:
https://huggingface.co/spaces/Qwen/Qwen-Audio
阿里云提供的有API(可能支持,没确认):
其它的针对语音的通用WebUI,API没有关注过。
Qwen2-Audio-7B (推荐)
Qwen2-Audio 是 Qwen 全新推出的大型音频语言模型系列。Qwen2-Audio 能够接收各种音频信号输入,并根据语音指令进行音频分析或直接提供文本响应。我们引入了两种不同的音频交互模式:
语音聊天:用户可以自由地与 Qwen2-Audio 进行语音交互,无需文字输入;
音频分析:用户在交互过程中可以提供音频、文字指令进行分析;
Qwen2-Audio-7B 和 Qwen2-Audio-7B-Instruct,分别是预训练模型和聊天模型。
语音聊天推理
在语音聊天模式下,用户可以自由地与 Qwen2-Audio 进行语音交互,无需文字输入:
python
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/guess_age_gender.wav"},
]},
{"role": "assistant", "content": "Yes, the speaker is female and in her twenties."},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/translate_to_chinese.wav"},
]},
]
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios = []
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]音频分析推理
在音频分析中,用户可以提供音频和文本指令进行分析:
python
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
{"type": "text", "text": "What's that sound?"},
]},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{"role": "user", "content": [
{"type": "text", "text": "What can you do when you hear that?"},
]},
{"role": "assistant", "content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property."},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
{"type": "text", "text": "What does the person say?"},
]},
]
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios = []
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(
librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]批量推理
python
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation1 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
{"type": "text", "text": "What's that sound?"},
]},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/f2641_0_throatclearing.wav"},
{"type": "text", "text": "What can you hear?"},
]}
]
conversation2 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
{"type": "text", "text": "What does the person say?"},
]},
]
conversations = [conversation1, conversation2]
text = [processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False) for conversation in conversations]
audios = []
for conversation in conversations:
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(
librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs['input_ids'] = inputs['input_ids'].to("cuda")
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)