主题
基于混合检索重排序策略的大模型增强方法
核心研究问题
如何优化检索增强生成(RAG)技术,特别是在知识库存储方式和检索结果重排序策略上,以显著提升大语言模型(LLM)在事实性问答任务中的准确率。
主要发现与贡献
知识库存储方式至关重要:段落切分优于固定长度切分
- 问题: 传统RAG系统常将知识库切分为固定长度(如256、512、1024字符)的文本块进行向量存储和检索。这种方式虽然处理效率高,但破坏了文本的自然段落结构信息。
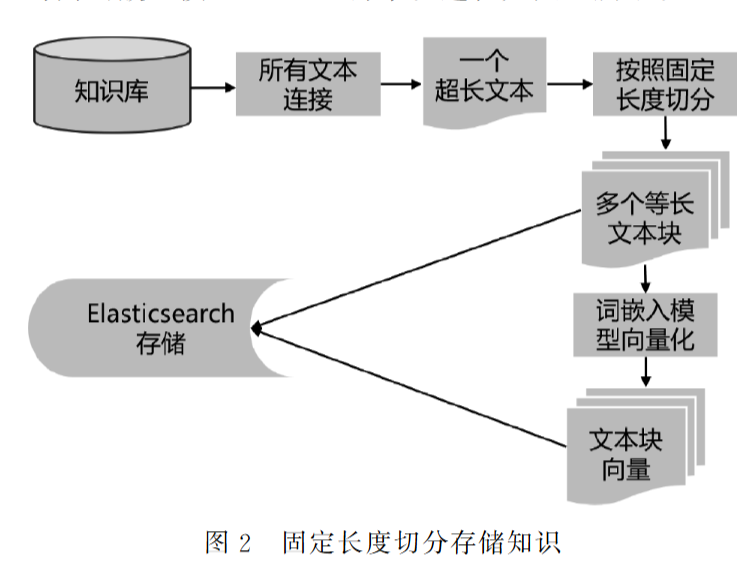
- 发现: 实验证明,将知识库按自然段落结构切分存储,相比固定长度切分,能大幅提升LLM依据检索知识回答问题的准确率(在多个模型上提升幅度可达10%-17%)。
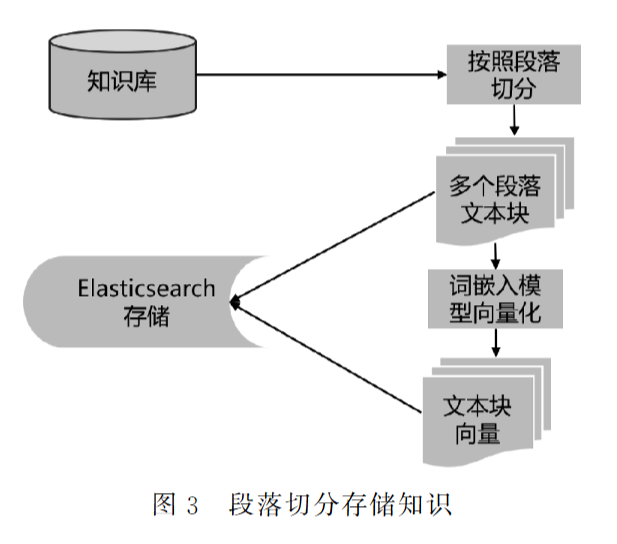
- 原因: 段落作为语义完整的单元,保留了上下文信息和逻辑结构,更利于LLM理解和利用知识。
重排序策略影响显著:逆序重排序在特定条件下效果更佳
背景: LLM对输入中关键知识的位置敏感(位置偏见)。随着LLM上下文窗口增长,研究重排序策略的影响变得有意义。
关键发现:
当检索到的知识段落被放置在用户问题之前(即Prompt设计为
Context + Question)时: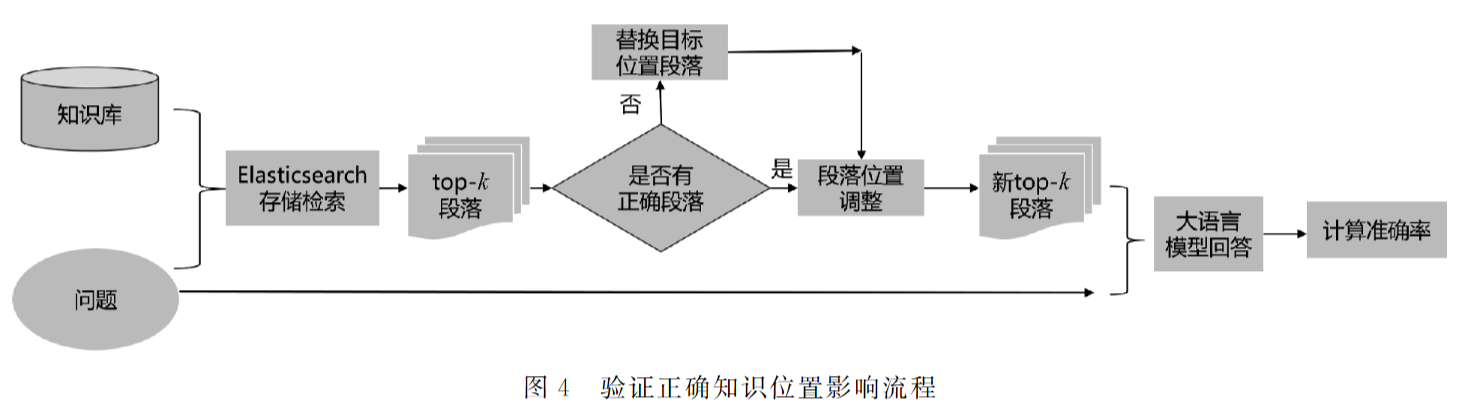
- 将最相关的知识段落(包含正确答案的段落)放置在检索结果列表的末尾(逆序),比将其放在开头(正序)或中间,更能提高LLM的准确率。
- 这种逆序优势随着提供给LLM的检索段落数量(k)的增加而变得更加明显(尤其在k=20, 30, 50时)。
解释: 在这种Prompt结构下,LLM似乎更倾向于关注和利用靠近问题(即输入末尾)的知识片段。将最相关知识放在末尾,使其处于LLM注意力更集中的区域。
提出并验证:基于混合检索的逆序重排序方法
动机: 传统的基于语义相似性(向量检索)的逆序虽然有效,但提升幅度有限(约1%)。需要一种更鲁棒的重排序方法。
方法:
混合检索:
结合两种检索方式的结果:
- 语义相似性检索(Semantic): 基于向量相似度,召回率高。
- 关键词匹配检索(Keyword): 基于词汇匹配,准确率高。
重排序:
采用倒数融合排序(Reciprocal Rank Fusion, RRF)的思想,但不直接加权分数,而是利用排名:
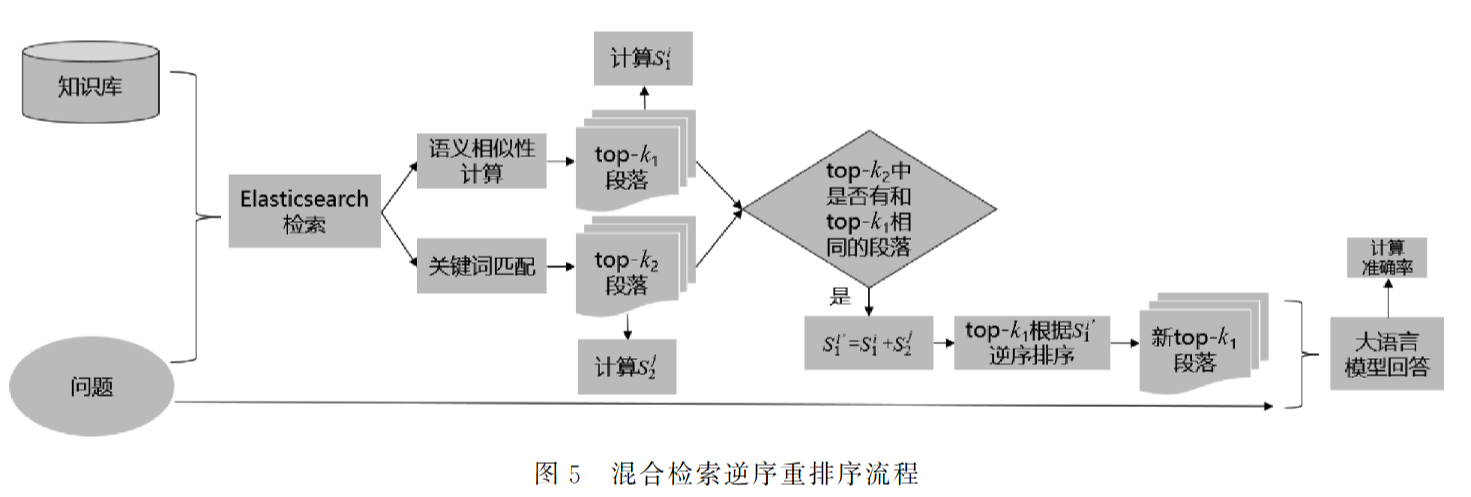
注意:这里是根据段落去切分的,也是根据段落是否相同来相加的
举个例子:
假设用户查询问题为:“苹果手机的最新功能”,需从知识库中检索相关段落。
通过两种独立检索方式得到结果:
语义相似性检索的 Top-3 结果:
- 段落A(介绍苹果公司发展史,排名得分最高)
- 段落B(详细描述iPhone 15的摄像头功能)
- 段落C(讨论智能手机市场趋势)
关键词匹配检索的 Top-3 结果:
- 段落D(解释“苹果”水果的营养价值)
- 段落B(iPhone 15的摄像头功能)
- 段落E(iOS系统更新日志)
RRF 融合步骤
- 计算排名倒数得分(公式:):
语义检索组:
- 段落A:
- 段落B:
- 段落C:
关键词组:
- 段落D:
- 段落B:
- 段落E:
- 合并相同段落的得分(公式:):
段落B同时出现在两组:
其他段落仅出现在单组,得分不变(如段落A保持1.0 )。
- 按总分逆序重排:
| 段落 | 总分 | 新排名(逆序) |
|---|---|---|
| B | 1.0 | 最后一位(最靠近问题) |
| A | 1.0 | 倒数第二位 |
| D | 1.0 | 倒数第三位 |
| C | 0.33 | 靠前位置 |
| E | 0.33 | 靠前位置 |
效果:
在检索召回率上:混合方法在Top-1和Top-10召回率上优于纯语义检索(尤其当k增大时)。
在LLM准确率上:
- 相比传统语义相似性检索(正序),该方法最高实现了4% 的准确率提升(在k=50时)。
- 相比传统语义相似性检索的逆序,最高实现了5% 的提升(在k=50时)。
- 相比混合检索的正序重排序,也能实现最高2% 的提升(在k=50时)。
优势在输入文本较长(k较大)时尤为显著。
- 其他重要发现与讨论(消融实验):
Prompt结构影响位置偏好:
Context + Question:LLM偏好利用末尾(靠近Question)的知识。逆序有效。Question + Context:LLM偏好利用开头(靠近Question)的知识。此时正序可能更有效。Question + Context + Question:位置偏好减弱,开头和末尾差异不大。- 总体而言,
Context + Question结构配合逆序重排序在该研究中表现最佳。
模型规模与位置偏见:
- 在测试的较小模型(6B, 13B)上,位置偏见(末尾优势)明显。
- 在超大模型(如GLM-3-Turbo)上初步实验也显示出末尾知识可能更受关注,但因模型常拒绝回答,结论需谨慎。
上下文失焦问题改进模型:
- 在声称解决“大海捞针”问题的模型(如GLM-4-9B-Chat-1M, Qwen2-7B-Instruct)上,位置偏见(开头vs末尾准确率差异)减弱(约1%),但依然存在。
- 中间位置的知识在这些模型上表现仍然最差,证明重排序仍有必要。
实验基础
- 数据集: 自建大规模中文段落级数据集(>85万段落),包含1000个经过筛选和修改的事实性问题(答案唯一且在特定段落中)。
- 系统架构: 构建了包含存储(Elasticsearch)、检索(语义/关键词/混合)、重排序(正序/逆序/混合逆序)、生成(LLM)的完整RAG流程。
- 评价指标: 主要使用准确率(Accuracy)评估LLM回答正确率,使用召回率(Recall@k)评估检索效果。
- 模型: 使用了多个开源中文LLM进行实验,包括ChatGLM3-6B-128k, XVERSE-13B-256K, Yi-6B-200K, GLM-4-9B-Chat-1M, Qwen2-7B-Instruct,并测试了GLM-3-Turbo API。
方案示例
用户问题:
“量子计算机的工作原理是什么?”
知识库段落(部分示例):
- 段落A:量子计算的基本概念(语义匹配度高,关键词匹配弱)
“量子计算机利用量子比特(qubit)存储信息,与传统二进制比特不同…”
- 段落B:量子纠缠与并行计算(语义+关键词均强)
“通过量子纠缠实现并行计算,例如Shor算法可高效分解大整数…”
- 段落C:量子退相干问题(语义相关,但非核心原理)
“量子退相干是量子计算的主要挑战,需通过纠错码缓解…”
- 段落D:量子比特物理实现(关键词匹配强,语义弱)
“超导电路、离子阱是实现量子比特的两种物理方案…”
混合检索逆序重排序流程
步骤1:混合检索
语义相似性检索(Top-3):
- 段落A(得分0.92)
- 段落B(得分0.85)
- 段落C(得分0.78)
关键词匹配检索(Top-3):
- 段落D(匹配“量子比特”“工作原理”)
- 段落B(匹配“并行计算”)
- 段落A(匹配“量子计算机”)
步骤2:RRF融合排序
计算排名倒数得分(公式:):
语义组:
- A:
- B:
- C:
关键词组:
- D:
- B:
- A:
合并相同段落得分():
- B:0.5 + 0.5 = 1.0
- A:1.0 + 0.33 = 1.33
- D:1.0(仅关键词组)
- C:0.33(仅语义组)
步骤3:逆序重排
| 段落 | 总分 | 新顺序(逆序) |
|---|---|---|
| A | 1.33 | 倒数第2位 |
| B | 1.0 | 倒数第1位(最靠近问题) |
| D | 1.0 | 倒数第3位 |
| C | 0.33 | 正序第1位 |
步骤4:输入LLM生成答案
- Prompt结构
(Context前置):
[段落C] [段落D] [段落A] [段落B]
根据以上信息,直接告诉我:量子计算机的工作原理是什么?- 效果:
核心段落B被置于最末位(紧邻问题),利用LLM对末尾信息敏感的特性(论文2.2节结论),提升答案准确性。
疑问:为什么A总分最高,而不是最靠近问题的?
- 逆序重排序的规则并非仅通过总分机械排序,而是结合了总分排序与相关性双重验证的优先级逻辑,具体来说:
- 段落B在两组检索中均被命中(语义+关键词),表明其相关性更全面(论文3.3.3节指出:混合检索可同时提高召回率与准确率)。
- 段落A仅在语义检索中排名靠前,关键词匹配较弱(排名第3),可能存在语义相关但关键词匹配不足的问题。
- 逆序重排序的规则并非仅通过总分机械排序,而是结合了总分排序与相关性双重验证的优先级逻辑,具体来说:
与传统方法对比
| 方法 | 输入顺序 |
|---|---|
| 语义相似性正序 | A→B→C→D |
| 语义相似性逆序 | D→C→B→A |
| 混合检索逆序(本文) | C→D→A→B |
总结与展望
该研究通过严谨的实验验证了知识库按段落存储以及采用基于混合检索的逆序重排序策略(尤其在知识前置、输入较长时)能显著提升LLM在RAG任务中的准确率。提出的混合逆序方法简单有效,无需训练。未来研究方向包括:探索更适用于超大模型的重排序策略、设计更有效的Prompt模板、以及进一步优化检索增强生成的整体流程。
版权声明
作者:Hang Shao
出处:https://www.cnblogs.com/pam-sh/p/18929904
版权:本作品采用「知识共享」许可协议进行许可。
声明:欢迎交流! 原文链接 ,如有问题,可邮件(mir_soh@163.com)咨询.