主题
lz4无损数据压缩
LZ4 是一种非常快的无损数据压缩算法,旨在实现极低的压缩和解压缩延迟。与其他压缩算法相比,LZ4 的压缩速度极高,尽管压缩率稍低。它广泛应用于实时数据压缩场景,尤其是在对性能要求苛刻的环境中,例如日志压缩、存储系统、网络传输等。
压缩原理
lz4压缩算法其实很简单, 举个例子
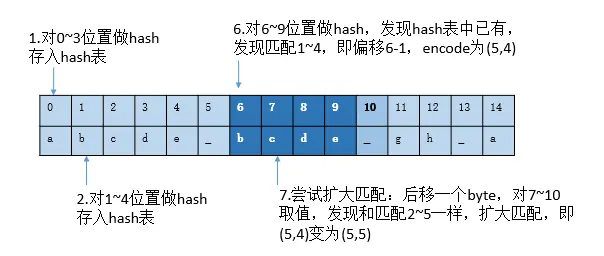
输入:abcde_bcdefgh_abcdefghxxxxxxx
输出:abcde_(5,4)fgh_(14,5)fghxxxxxxx其中两个括号内的便代表的是压缩时检测到的重复项,(5,4) 代表向前5个byte,匹配到的内容长度有4,即"bcde"是一个重复。当然也可以说"cde"是个重复项,但是根据算法实现的输入流扫描顺序,我们取到的是第一个匹配到的,并且长度最长的作为匹配。
压缩格式
压缩后的数据是下面的格式

输入:abcde_bcdefgh_abcdefghxxxxxxx
输出:tokenabcde_(5,4)fgh_(14,5)fghxxxxxxx
格式:[token]literals(offset,match length)[token]literals(offset,match length)....其他情况也可能有连续的匹配:
输入:fghabcde_bcdefgh_abcdefghxxxxxxx
输出:fghabcde_(5,4)(13,3)_(14,5)fghxxxxxxx
格式:[token]literals(offset,match length)[token](offset,match length)....这里(13,3)长度3其实并不对,match length匹配的长度默认是4
Literals: 没有重复、首次出现的字节流,即不可压缩的部分
Match: 重复项,可以压缩的部分
Token: 记录literal长度,match长度。作为解压时候memcpy的参数
压缩率
可以想到,如果重复项越多或者越长,压缩率就会越高。上述例子中"bcde"在压缩后,用(5,4)表示,即从4个bytes压缩成了3个bytes来表示,其中offset 2bytes, match length 1byte,能节省1个byte。
算法实现
大致流程,压缩过程以至少4个bytes为扫描窗口查找匹配,每次移动1byte进行扫描,遇到重复的就进行压缩。
由于offset用2bytes表示,只能查找到到2^16(64kb)距离的匹配,对于压缩4Kb的内核页,只需要用到12位。
扫描的步长1byte是可以调整的,即对应LZ4_compress_fast机制,步长变长可以提高压缩解压速度,减少压缩率。